从一个越写越慢的编辑器中聊聊优化思路
增订 | 2020年8月9日
TEditor 维护了一个解析状态栈。逐个读入字符,结合当前解析状态进行状态转换,将旧状态推入栈中,以模仿解析 HTML 的层级结构。状态栈的入栈、出栈过程,通过 DIG_IN、DIG_OUT 来维护,这两个函数会触发更新标签流的副作用。
因为处理整段字符也只需要一次循环;要维护的状态大体上来说只有零散的几个变量和一个状态栈;没有用正则匹配;再加上每解析过程和正常的 Markdown 解析器不一样,TEditor 最大段落只支持到行,再加上每行都做了 LFU 缓存。所以理论上来说 TEditor 应该相当快... 不过,随着解析器的功能增强,状态维护变得有点困难,特别乱。反正我现在是很难看懂我以前写了啥玩意儿...
整个系统的状态转变则是发生在许许多多小的、细微的状态变化混合来形成的。这些相互关联的状态变化形成了一个概念上的“状态网”,我们时不时会因它而感到困惑。
《JavaScript 函数式编程》
经过一年的 JS 学习,我的 JS 水平提高了不少。近期我重写了这个 Markdown 解析器,Markdown Parser,舍弃了“状态转换”的概念,用回了正则匹配 + AST。虽然说速度可能变慢了一个量级,不过可扩展性还是非常强的,比如说可自定义解析插件,介入解析过程。有空还是得学习 Markdown-It 的源码,那玩意儿是我的目标...
原文
你用过一个越写越慢的编辑器么?
我曾在项目中实现了一个 MD 编辑器,用来解析简单的 MD 文本,不过它的性能令我捉急。初期基本没有做任何性能优化相关的内容,导致每当我正在写的文章变长之后,编辑器会变得非常非常卡,所以说是越写越慢的编辑器( ╯□╰ ) 这期文章主要针对这个编辑器聊聊我实践以及思考总结的一些性能优化方法,肯定还有文中没有总结到的一些方法,欢迎各位看官不舍赐教,留言评论。
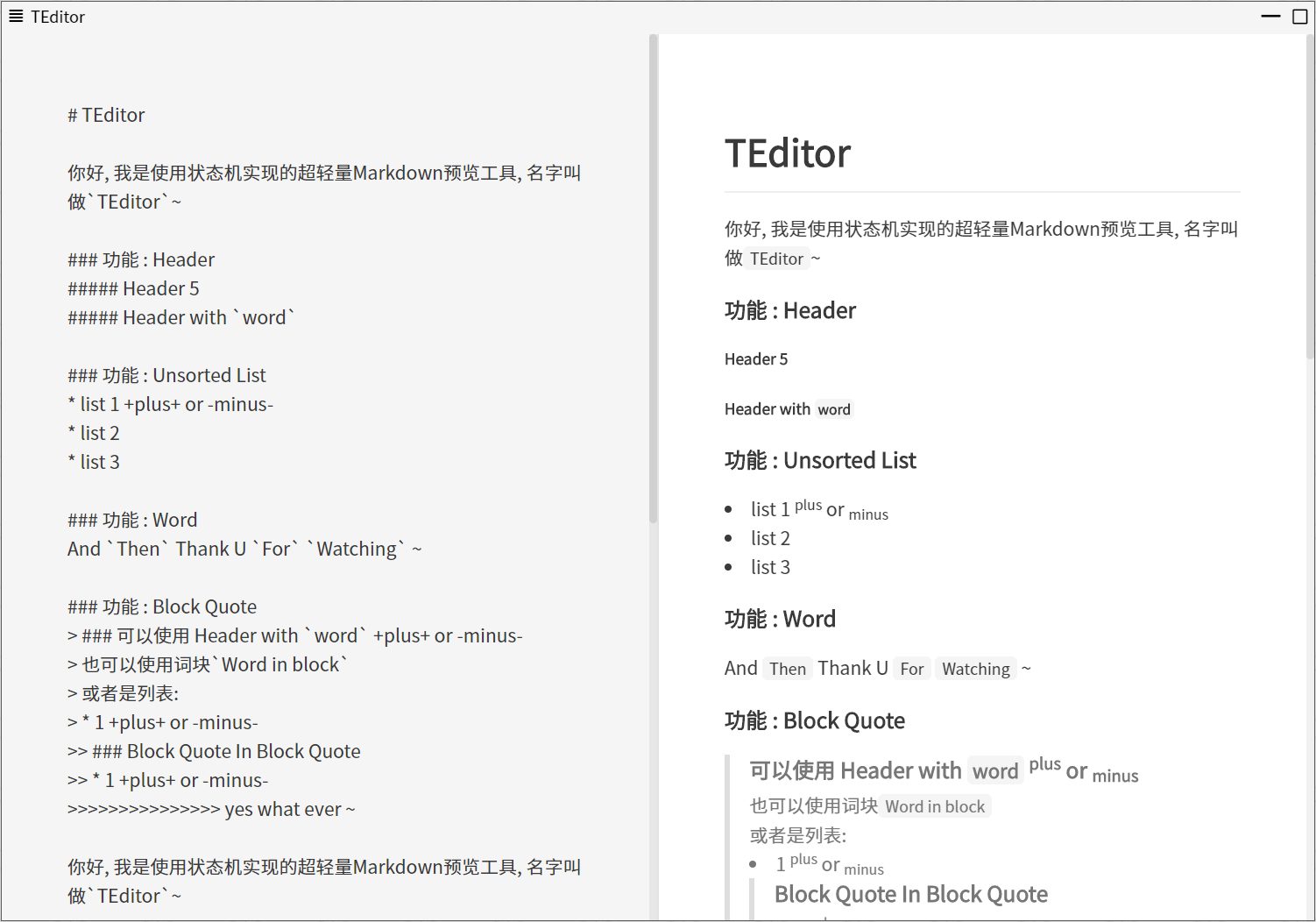
解析过程简述
文中 MD 编辑器可以在左侧窗口输入 MD 格式文本,然后通过调用解析函数将文本解析转换为 HTML 代码,放到右侧 v-html 窗口中直接渲染。
一般来说 MD 解析不需要经过词法语法分析,而且标点符号几乎没有二义性,解析起来比较简单。对于一段简单的 MD 文本,我们大可从一个正则表达式的角度入手。思考从以下 4 点开始匹配:
- 解析块状元素,分割线,引用块,代码段等
- 解析文本元素,标题,列表,以及普通文本内容
- 解析行内元素,角标,加粗,斜体等
我们以以下文本为例进行解析:
### 一个*斜体*标题
首先命中文本元素标题,内容为一个*斜体*标题
紧接着,继续解析比文本元素优先级更低的行内元素,这次命中行内元素斜体,内容为斜体
至此,我们将解析完的内容推入结果数组,结果形如:
parsedContent = [`<h3>一个<i>斜体</i>标题</h3>`]
如果文本不是一行,再继续之前的思路继续解析,直到原始内容为空,得到最终的解析结果。
解析函数节流
函数节流是老生常谈的话题了,当然不能当左侧内容一有变动就立即更新。在一些极端的场合,比如长按删除或是长按空格回车等情况下,连续执行解析函数硬件会造成沉重的负担。所以我们优化思路首先要求尽量在不太影响视觉效果的情况下,尽可能少地执行解析函数。
目标有了,那么对应的解决方案手到擒来:
- 对特定类型按键,我们将不调用解析函数,如多个连续的空格回车或是某些行内符号。因为这些内容的解析结果对之后预览结果没有影响
- 对解析函数节流,将调用频率控制在 0.3 秒 1 次,具体的数值可根据个人需求调整,比如我常常在回车后习惯性扫一眼预览,那么按回车后可以跳过节流立即执行一次解析
缓存解析结果
缓存解析结果方案,类似于算法题中常见的缓存对象。比如我们要实现一个斐波那契数列递归函数,计算fabi(5)时需要用到fabi(3)和fabi(4)的结果,如果我们有缓存,我们可以直接从缓存中获取fabi(3)的结果。将这一概念推导到解析器,我们可以创建一个对象去缓存解析结果。
备忘录实现
一开始写解析结果缓存的时候,我犯了一个很严重的错误,那就是想尝试将所有内容以及其解析值缓存到备忘录对象,代码形如:
data: {
// 缓存对象
memo: {}
}
watch: {
// 当编辑器的value变动时将尝试直接获取缓存,如果没有缓存才解析内容
value (n,o) {
if (this.memo[n]) {
this.parsedValue = this.memo[n]
} else {
this.memo[n] = this.parsedValue = parseMDToHTML(n)
}
}
}
代码看起来没什么问题,因为问题不在代码。
问题在内存容量上。
代码运行在浏览器中,一般情况下,内存相对于代码执行速度而言是比较廉价的,所以我经常使用到用对象进行缓存这种以空间换时间的代码模式。一般情况下它非常好用,但它可能带来一个问题。这种代码模式进一步限制了前端对内存的感知——我将整个编辑区域的原始值作为对象的键,将其解析结果作为值缓存下来——一旦文章长度开始增长,缓存对象占用的内存容量将急剧增大。
假设我们有某文章字符长度总量为 n,那么备忘录模型将生长成这个样子:
value = [1,2,3,...,n-1,n].join('')
memo == {
'1': '1',
'12': '12',
'123': '123',
// ...
'12345...n-1': '12345...n-1',
'12345...n': '12345...n',
}
那么可以轻易得出,文章字符长度(N)和内存消耗量(O)的关系,形如:
$$O = N(N+1)/2 ≈ N^2$$
和你想的一样,我浏览器内存爆了 😅
不仅如此,文章不断地增长,不仅带来内存压力,解析函数每次要处理地内容也变多,浏览器响应速度也越来越慢。
我们亟需更好的缓存方案。
LRU 以及 LFU 策略
在解析过程简述小节,我们提到解析器在解析时,会将 MD 文本分为块状内容进行解析。由此我们可以尝试缓存块状内容的解析结果,而不是去缓存全文。为了在这次优化不爆内存,我们引入有限空间概念——设想编辑器内含一个数组,用来存放 MD 文本中块状内容以及其解析结果,同时数组有最大长度限制,限制为 1000,假设我们的每一个元素占 5kb 的内存,那么这个数组将只占浏览器约 5MB 的内存,无论我们怎么折腾,至少不至于爆内存了~
不过我们需要先考虑这样一种情况,假使我们的文章有超过 1001 个块状内容,那么多出的这一个块状内容进行解析后得到的结果很显然不能直接存入长度限制为 1000 数组中。所以我们需要一种算法去计算应该舍弃数组中哪一个元素,将该元素舍弃后,再把我们手中结果存入数组。
用过 Redis 的朋友应该了解,Redis 作为一种使用内存作缓存的缓存系统,它有多种缓存策略:
- 基于数据访问时间进行淘汰(LRU : Least Recently Used 淘汰最近时间最少使用到的内容)
- 基于访问频率进行淘汰(LFU : Least Frequently Used 淘汰访问频次最低的内容)
下文将仿照 Redis 的缓存淘汰策略手动造一个使用 LFU 策略进行缓存淘汰的缓存类。
简单的链表实现
实际的代码并未采用数组充当缓存元素,实际选择了双向链表,使用双向列表可以抹除使用出租移除元素添加元素带来的性能成本。
我们需要提前定义好节点类Node:
function Node (config) {
this.key = config.key
this.prev = null
this.next = null
this.data = config.data || {
val: null,
weight: 1
}
}
// 将当前节点的next指向另一节点
Node.prototype.linkNextTo = function (nextNode) {
this.next = nextNode
nextNode.prev = this
}
// 将当前节点插入某一结点后
Node.prototype.insertAfterNode = function (prevNode) {
const prevNextNode = prevNode.next
prevNode.linkNext(this)
this.linkNext(prevNextNode)
}
// 删除当前节点,除非节点是头节点/尾节点
Node.prototype.unLink = function () {
const prev = this.prev
const next = this.next
if (!prev || !next) {
console.log(`Node : ${this.key} cant unlink`)
return false
}
prev.linkNext(next)
}
缓存类
缓存类将内含一个双向链表,同时还包含最大链表节点数,当前链表长度这些属性:
数组可以直接通过下标去获取某个特定的元素,而链表不行,在缓存类中我使用一个备忘录对象去记录每一个节点的访问地址,充当数组下标的作用,详见下代码中`nodeMemo`的使用
function LFU (limit) {
this.headNode = new Node({ key: '__head__',data: { val: null,weight: Number.MAX_VALUE } })
this.tailNode = new Node({ key: '__tail__',data: { val: null,weight: Number.MIN_VALUE } })
this.headNode.linkNext(this.tailNode)
this.nodeMemo = {}
this.nodeLength = 0
this.nodeLengthLimit = limit || 999
}
// 通过key判断缓存中是否有某元素
LFU.prototype.has = function (key) {
return !!this.nodeMemo[key]
}
// 通过key获取缓存中某一元素值
LFU.prototype.get = function (key) {
let handle = this.nodeMemo[key]
if (handle) {
this.addNodeWeight(handle)
return handle.data.val
} else {
throw new Error(`Key : ${key} is not fount in LFU Nodes`)
}
}
// 通过key获取缓存中某一元素权重
LFU.prototype.getNodeWeight = function (key) {
let handle = this.nodeMemo[key]
if (handle) {
return handle.data.weight
} else {
throw new Error(`Key : ${key} is not fount in LFU Nodes`)
}
}
// 添加新的缓存元素
LFU.prototype.set = function (key,val) {
const handleNode = this.nodeMemo[key]
if (handleNode) {
this.addNodeWeight(handleNode,10)
handleNode.data.val = val
} else {
if (this.nodeLength < this.nodeLengthLimit) {
this.nodeLength++
} else {
const deleteNode = this.tailNode.prev
deleteNode.unLink()
delete this.nodeMemo[deleteNode.key]
}
const newNode = new Node({ key,data: { val,weight: 1 } })
this.nodeMemo[key] = newNode
newNode.insertAfter(this.tailNode.prev)
}
}
// 打印缓存中全部节点
LFU.prototype.showAllNodes = function () {
let next = this.headNode.next
while (next && next.next) {
console.log(`Node : ${next.key} has data ${next.data.val} and weight ${next.data.weight}`)
next = next.next
}
}
// 对某一元素进行加权操作
LFU.prototype.addNodeWeight = function (node,w = 1) {
const handle = node
let prev = handle.prev
handle.unLink()
handle.data.weight += w
while (prev) {
if (prev.data.weight <= handle.data.weight) {
prev = prev.prev
} else {
handle.insertAfter(prev)
prev = null
}
}
}
另附测试用例
import LFU from '@/utils/suites/teditor/LFU'
describe('LFU测试',() => {
const LFU = new LFU(4)
it('能够正确维护链表长度',() => {
LFU.set('1',1)
LFU.set('2',2)
LFU.set('3',3)
LFU.set('4',4)
LFU.set('5',5)
expect(LFU.has('4')).to.equal(false)
})
it('节点的数据应该正确',() => {
expect(LFU.get('1')).to.equal(1)
expect(LFU.get('2')).to.equal(2)
expect(LFU.get('3')).to.equal(3)
expect(LFU.get('5')).to.equal(5)
LFU.get('5')
LFU.get('3')
LFU.get('3')
LFU.get('3')
LFU.get('3')
LFU.set('5',6)
expect(LFU.get('5')).to.equal(6)
})
it('节点的权重应该正确',() => {
expect(LFU.getNodeWeight('5')).to.equal(14)
expect(LFU.getNodeWeight('3')).to.equal(6)
})
})
拆分渲染内容
拆分渲染内容和通过节流解析函数想要达到的目的类似——通过限制浏览器的重绘回流次数以减轻硬件负担。
我的解析函数会将传入的 MD 文本解析为 HTML 片段,然后通过 v-html 将片段放到浏览器右侧窗口进行渲染,虽然我们在解析函数中做了缓存,使得解析速度增加,但是每一次的解析都会使浏览器重新绘制整一个右侧窗口,这里有一个优化点。
拆分渲染内容就是要解决这样一个问题。我们把右侧窗口一整块 v-html 区域以 MD 块状元素拆分为多个小的 v-html 区域,当编辑器某一行的文本数据有变动时,只通知右侧窗口更新对应区域的内容,这样一来,浏览器性能可以得到进一步提升。
总结
前端做页面性能优化时,除了网络层面的优化,剩下很大一块内容都落在 JS 和浏览器的头上,考虑 JS,主要是如何减少重复计算,至于浏览器,则主要会想到重绘回流这块。依靠这两大山头,相信你也能写出运行速度飞快的代码!
本文只对代码做了概括性说明,具体的代码细节还需要待我使劲整理再发一篇新文章,比如<动手撸一个简单的 LFU 缓存类>之类的 😀,敬请期待~