💻 本地部署 Qwen 翻译网页
增订 | 2025-12-20
发现沉浸式翻译对一连串的请求有优化,所以不再使用自定义服务器转发,而是通过添加自定义服务来实现。
因为 LM Studio 的 API 是 OpenAI 兼容的,所以自定义服务选 OpenAI。

然后把配置都填一下。以我的配置为例:APIKEY 随便填,模型填你在 LM Studio 下载的模型名称,自定义 API 接口地址可以填 http://localhost:1235/v1/chat/completions。

最后是安装 nginx,把请求转发到本地 LM Studio 的服务器上。因为沉浸式翻译插件发起的请求会有 CORS 限制,所以需要在 nginx 里统一添加 CORS 相关的头信息。
以下是一个简单的 nginx 配置示例:
# lm studio :1234
server {
listen 127.0.0.1:1235 ssl;
server_name 127.0.0.1;
ssl_certificate ./ssl/localhost.crt;
ssl_certificate_key ./ssl/localhost.key;
location / {
# 隐藏后端返回的 CORS 相关头
proxy_hide_header Access-Control-Allow-Origin;
proxy_hide_header Access-Control-Allow-Methods;
proxy_hide_header Access-Control-Allow-Headers;
proxy_hide_header Access-Control-Allow-Credentials;
proxy_hide_header Access-Control-Expose-Headers;
# nginx 统一设置 CORS 头
add_header 'Access-Control-Allow-Credentials' 'true' always;
add_header 'Access-Control-Allow-Origin' '<插件ID>' always;
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE' always;
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization,Api-Key' always;
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range' always;
# 处理 OPTIONS 预检请求
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Credentials' 'true' always;
add_header 'Access-Control-Allow-Origin' '<插件ID>' always;
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE' always;
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization,Api-Key' always;
add_header 'Access-Control-Max-Age' 1728000 always;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 204;
}
proxy_pass http://127.0.0.1:1234;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
我本地是用的 HTTPs,所以 nginx 还会涉及到证书配置,也许删掉 ssl 相关配置,直接调 http 也行,没测试过。但如果会报错的话,可以使用 mkcert 来生成本地受信任的证书。
brew install mkcert
mkcert -install
mkcert -key-file key.pem -cert-file cert.pem localhost 127.0.0.1 ::1 192.168.100.56 -install
这之后还要修改下 nginx 配置里的 <插件ID>。把它替换成沉浸式翻译插件的 ID,可以通过打开浏览器调试工具,然后发送一个测试请求,
在 Network 选项卡里查看请求的 Request Headers 里的 Origin 字段来获取。

fetch("https://127.0.0.1:1235/v1/chat/completions", {
"headers": {
"api-key": "1234567890",
"authorization": "Bearer 1234567890",
"content-type": "application/json"
},
"referrer": "",
"body": "{\n \"model\": \"qwen/qwen3-next-80b\",\n \"temperature\": 0,\n \"messages\": [\n {\n \"role\": \"system\",\n \"content\": \"你是一个专业的简体中文母语译者,需将文本流畅地翻译为简体中文。\\n\\n## 翻译规则\\n1. 仅输出译文内容,禁止解释或添加任何额外内容(如\\\"以下是翻译:\\\"、\\\"译文如下:\\\"等)\\n2. 返回的译文必须和原文保持完全相同的段落数量和格式\\n3. 如果文本包含HTML标签,请在翻译后考虑标签应放在译文的哪个位置,同时保持译文的流畅性\\n4. 对于无需翻译的内容(如专有名词、代码等),请保留原文\\n\\n## Context Awareness\\nDocument Metadata:\\nTitle: 《Options》\\n\\n\"\n },\n {\n \"role\": \"user\",\n \"content\": \"翻译为简体中文(仅输出译文内容):\\n\\nHello world\"\n }\n ]\n}",
"method": "POST",
"mode": "cors",
"credentials": "include"
})
如果你的 LM Studio 开启了局域网访问,为了安全起见,你也可以设置 APIKEY 然后在 nginx 校验一下,反正看个人需求吧,这不非必选。
最后启动 nginx,然后测试下服务没问题就可以了。
这种方法的性能要比自己写服务器转发好很多,而且配置也更简单。
此外,LM Studio 推出了官方 API。使用官方 API 可以在工程化方面做得健全一些,见:lmstudio-js
前言
平常经常逛技术类的英文独立博客比较多,但是英文很菜,只能看懂一些简单的文章,所以常依赖沉浸式翻译浏览器插件去阅读一些更难或更书面化的英文网站。
相比常见的划词翻译,沉浸式翻译可以几乎不受限制地调用 DeepL、OpenAI 等第三方 API,翻译大段句子;他还提供了翻译整个页面、自定义快捷键等额外的功能。使用了四个月的沉浸式翻译带来最直观的感受是:用 AI 翻译(LLM) 得到的译文质量真是特喵的好!只是,苦于这个插件高昂的价格(69 软妹币每月的价格实在太贵,再加点钱我都能整个 OpenAI 的 Pro 会员了),本着能本地白嫖就不线上付费的原则,我本地部署了一个 LLM 专门用来翻译网页或文档。
直接说结论。相比 Google 或百度等机翻,AI 翻译在语句通顺程度、语气、名词保留等方面好得多。尽管测试下来(主观来看),开源 LLM 模型的翻译质量还差 GPT3.5 一截,而且也容易出稀奇古怪的问题,但实话说(习惯就好)
已经够用了。
大体思路
机器是 MacBook Pro M3 Max,因为 Mac 的内存和显存能公用,所以本地部署模型时一般不用担心爆显存。以下本地部署的方法不一定适合 Windows 的笔记本,仅供参考。外接或魔改卡富哥请忽略我。另接触这些内容不久, 所以如果有错误还请佬们评论区指出。
模型管理工具
首先要选择一个合适的本地模型管理工具。工具最好要带服务器功能,这样能省去很多代码方面的麻烦。此外,使用工具管理模型非常方便,有飞机的情况下,一般都是一键下载什么的。题外话,由于模型文件都比较大,所以需要注意流量, 刚玩的这两周我花了 200GB 流量,都用在下载各种稀奇古怪的模型上了。
相比上手最简单的 Ollama,我推荐有 GUI 界面的 LMStudio。LMStudio 除了聊天、服务器功能,还支持多个模型比对等更好玩的东西,还能在界面上快速设置如 GPU 加速、提示词格式、停止词、上下文长度等参数。对新手来说比较友好。
安装好 LMStudio 后,首要任务是下载模型。
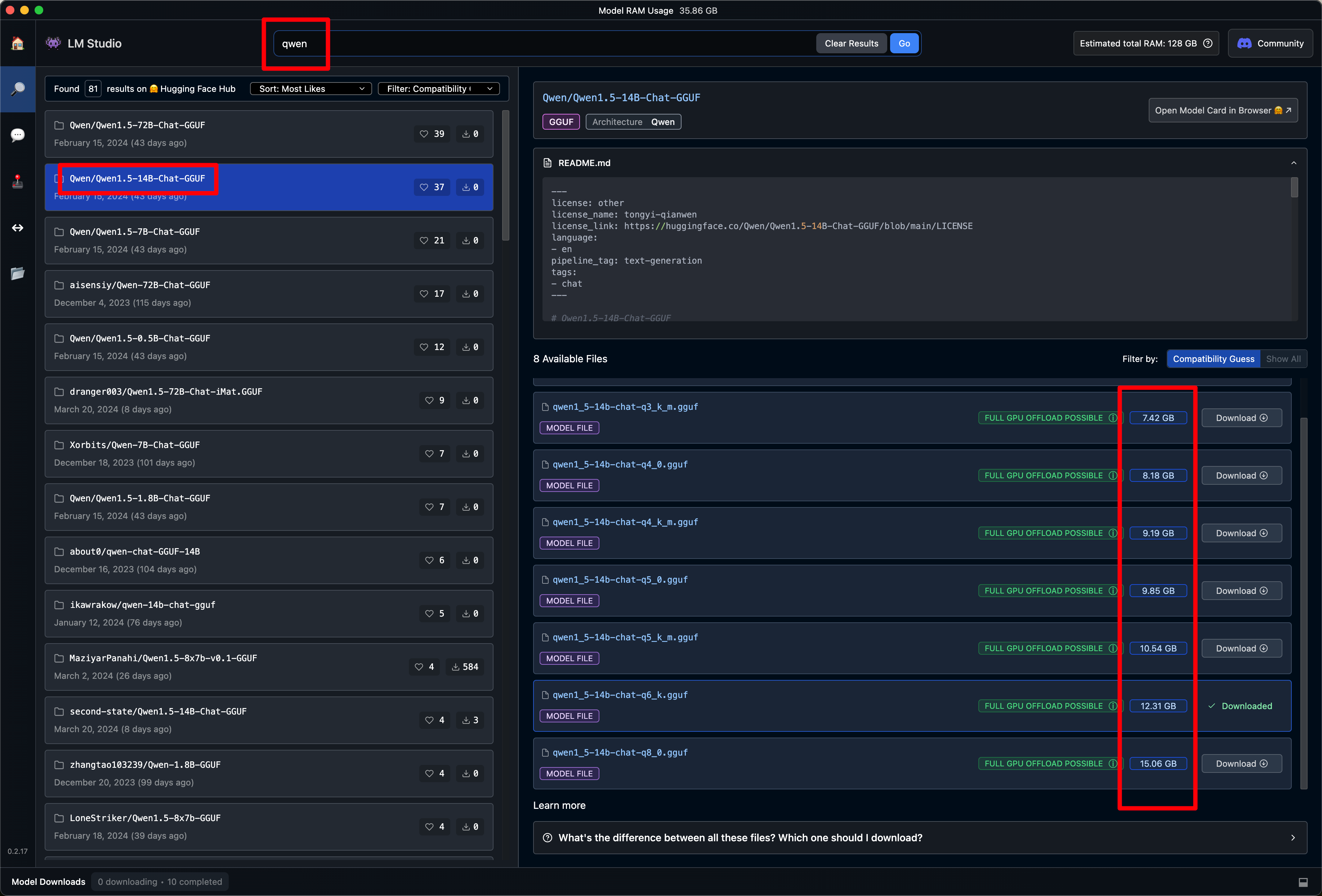
如果不想浪费时间自己搜索以及测试模型,直接按照下图下载评分不错且有中文支持的 Qwen 模型就好。模型名称中的 Q2、Q6_k 等后缀是指模型的压缩策略,同种模型的 Q8 量化比 Q2 量化效果好,但是推理计算量更大,体积更大( 显存占用更大)。LMStudio 显示了模型的体积,所以选 Qwen/Qwen_1.5_14B_Q6 还是 Qwen/Qwen_1.5_14B_Q2 就按照机器决定吧。举个例子,如果你的 Mac 内存是 32GB, 那选个 16GB 大小的 Qwen_1.5_14B_Q8_0 就可以。
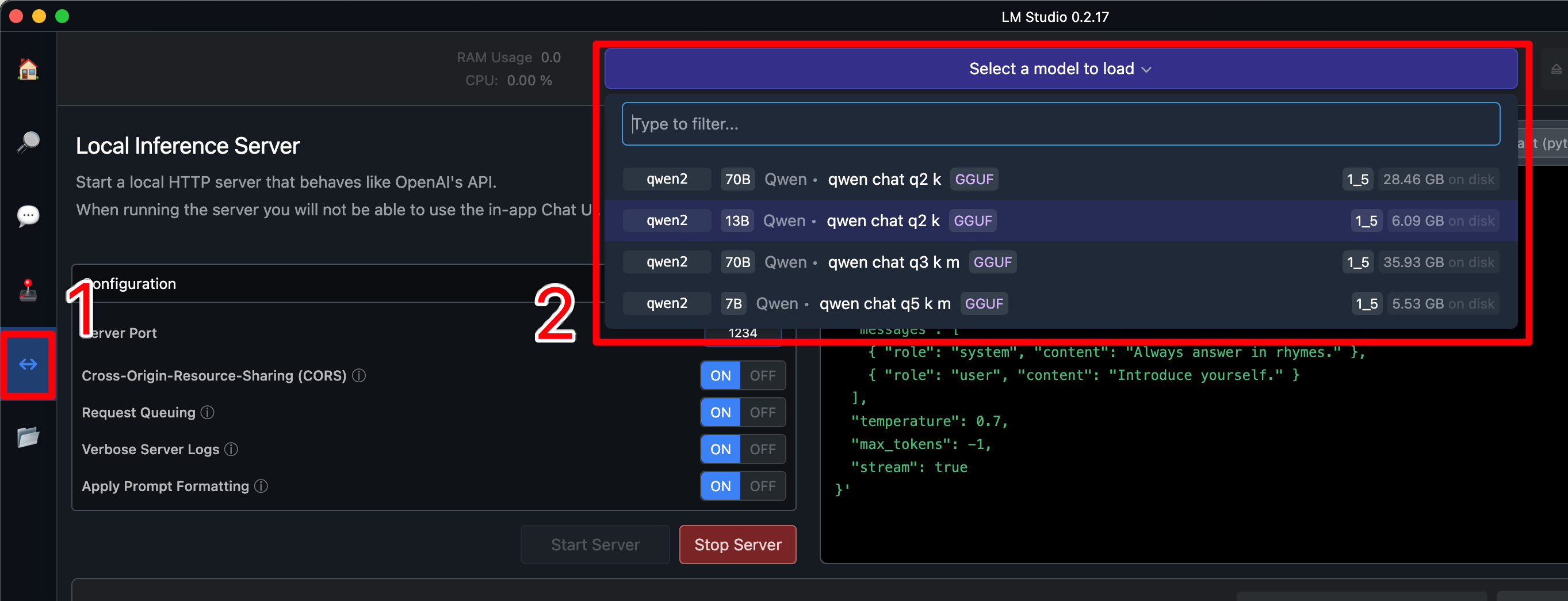
随后,打开 LMStudio 的 Server 页面(①)。启动服务器前前需要选择一个模型(②)。选好后等它加载一段时间,再点击下面那个 “Start Server” 就能成功启动。
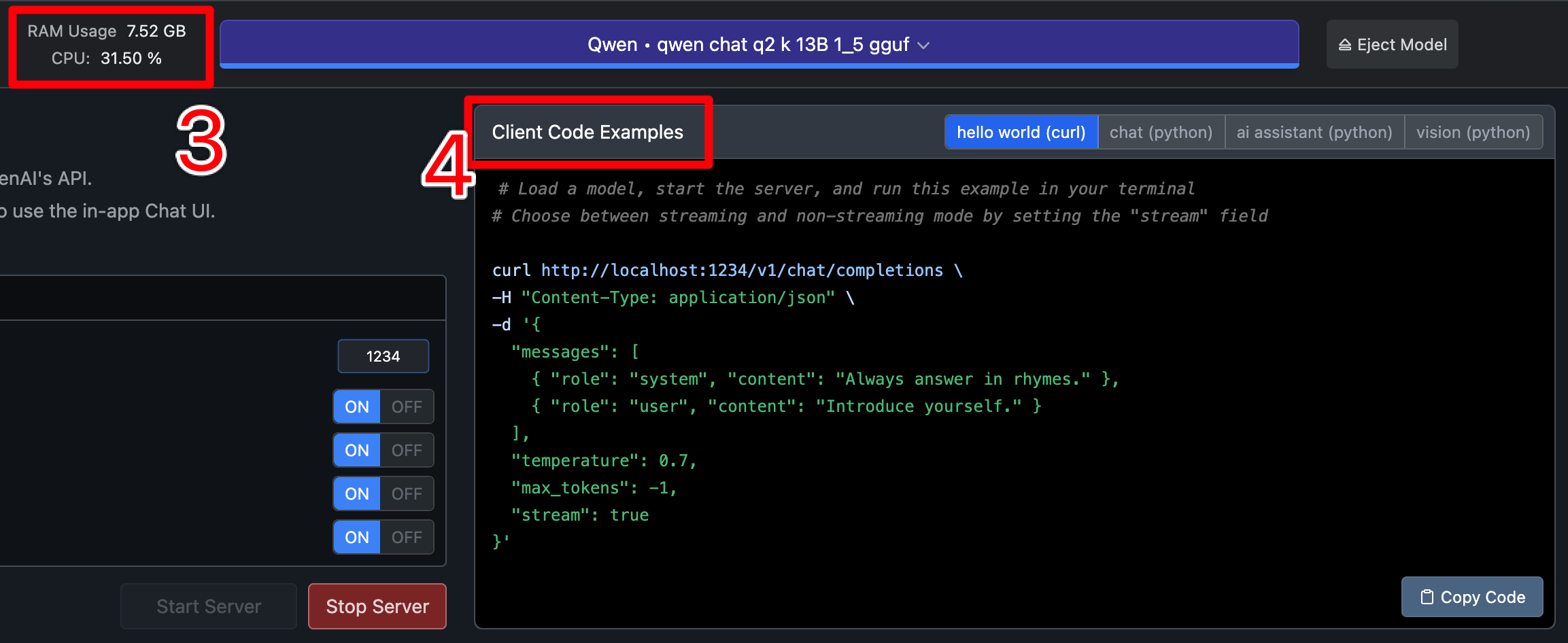
一旦 LMStudio 的服务器成功启动,可以复制测试代码(④)到终端运行,看看模型是否能正常工作。界面上能看到对应模型占用的显存资源以及运行任务时 CPU 占用情况(③),可视机器负载情况更换模型( 也可以在右侧配置中降低 n_ctx 上下文长度)。
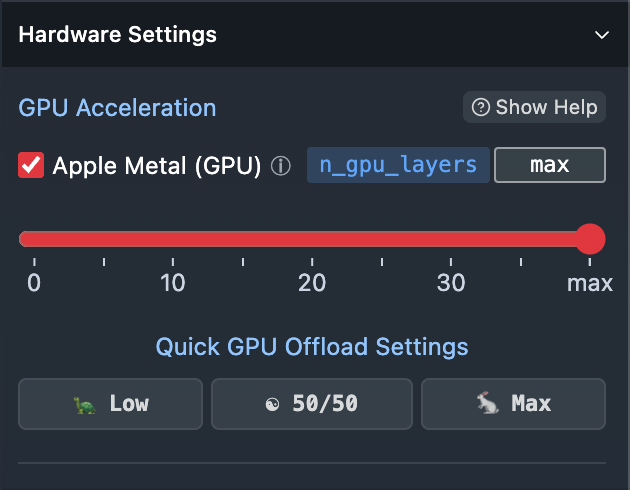
M3 的机器只要内存够可以拉满右侧面板的 GPU Layers,速度会快不少。题外话,如果你想知道 M3 和 4090 比速度的话... 算了,还是别比了,已经花了不少钱买了库克的黄金内存,没必要在 GPU 的性能比较上再捅自己一刀。
本地服务器转发
沉浸式翻译的 API 格式和 LMStudio 的 API 格式不能无缝对接,所以启动完 LMStudio Server 后,我们需要写一个本地服务器用来中转翻译插件的请求。题外话,也许有现成的工具,有知道的佬请踢我一脚。
下图有一个简单的本地服务器示例,使用了 Koa 框架,按照沉浸式翻译文档提供的 API 格式获取数据,然后用 fetch 打给 LMStudio,拿到译文后,组装好结果后返回。完整示例代码我上传到了 Github simple-local-llm-server@Lionad-Morotar,有需要自取。
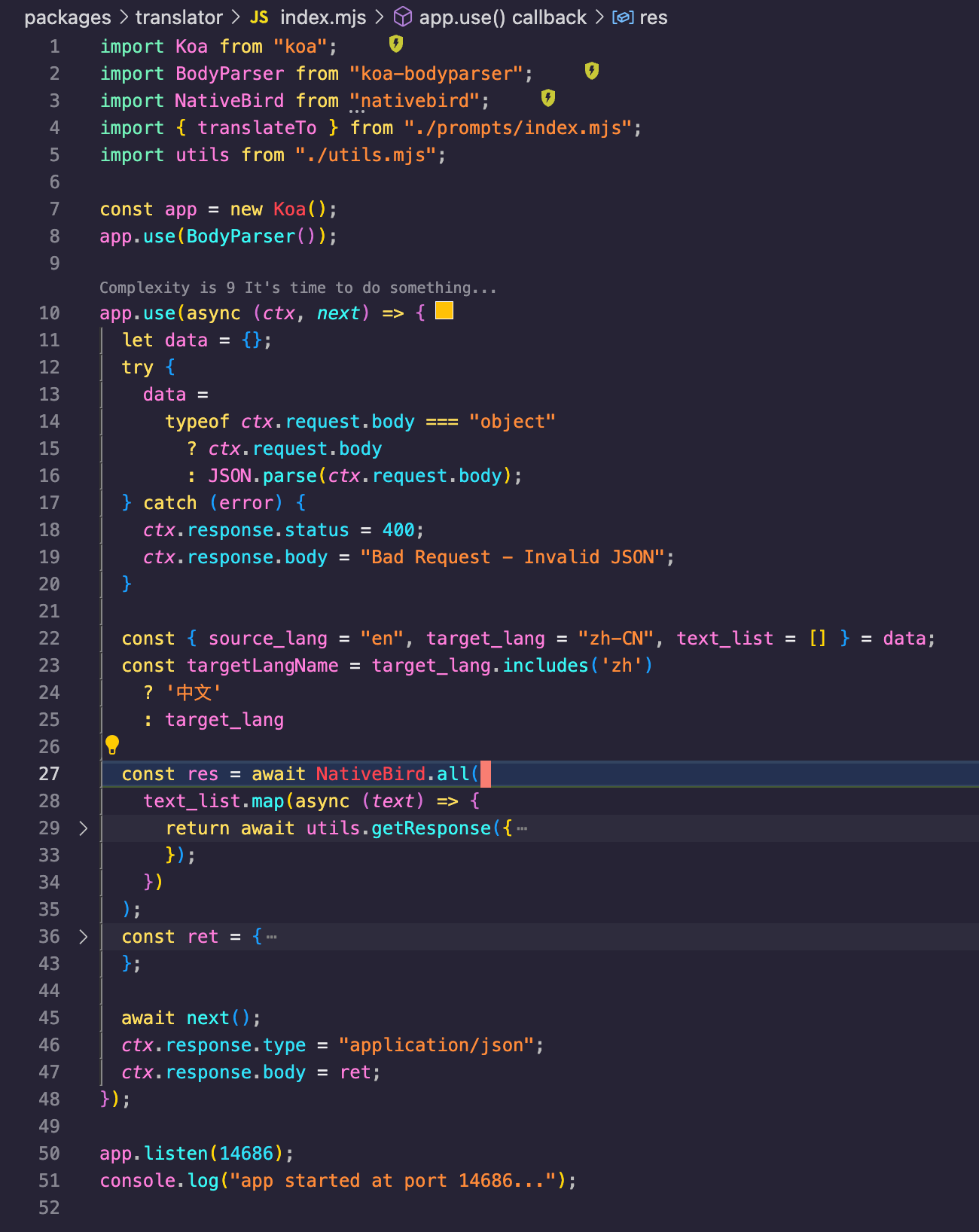
其中 utils.getResponse 便是向 LMStudio 发起请求。选择完 Qwen 模型后,LMStudio 的 API 会要求提供 system 以及 user 两种角色的入参,用于设置模型推理的上下文, 所以需要手动设置一下提示词。以下是 getResponse 实现的示例。
const data = {
messages: [
{
role: "system",
content: `You are a highly skilled translator with expertise in many languages. Your task is to translate any provided text and translate it into ${targetLang} while preserving the meaning, tone, and nuance of the original text. Please maintain proper grammar, spelling, and punctuation in the translated version. Only include the translated text and do not include any additional information, explanations, or unrelated content. For example, user input "Ask HN: Can we do better than Git for version control?", you return, 来自 Hacker News 的问题: 在版本控制方面,我们能做得比 Git 更好吗?`,
},
{
role: "user",
content: "translate into Chinese: " + opts.user,
},
],
temperature: 0.5,
max_tokens: -1,
stream: false,
};
const response = await fetch("http://localhost:1234/v1/chat/completions", {
headers: {
Accept: "application/json",
"Content-Type": "application/json",
},
method: "POST",
body: JSON.stringify(data),
}).then((res) => {
return res.json();
});
测试本地服务器的时候我碰到了有几个小问题,各位也可以留意一下:
一个是停止词的问题。尽管 LMStudio 默认的停止词包含了换行,但 Qwen 1.5 13B 经常一连输入几百个换行符,占用推理时间。一开始没有找到解决办法,只好把 max_tokens 设置为和输入文本长度一样( 中文译文几乎都比英文短),这样一来最多也就多输出几个换行符,之后在代码里手动 trim 一下就能得到正确结果。后来换了模型就没碰到过这个问题了。
二是关于请求安全。如果只想让沉浸式翻译浏览器插件调用这个 API,需要手动校验一下 Referer,只要来源是 chrome-extension:xxx 就可以。具体的 extensionId 可以在浏览器插件的管理页面看到。
插件设置
最后是沉浸式翻译插件的设置,首先要在开发者设置里打开 Beta 功能。
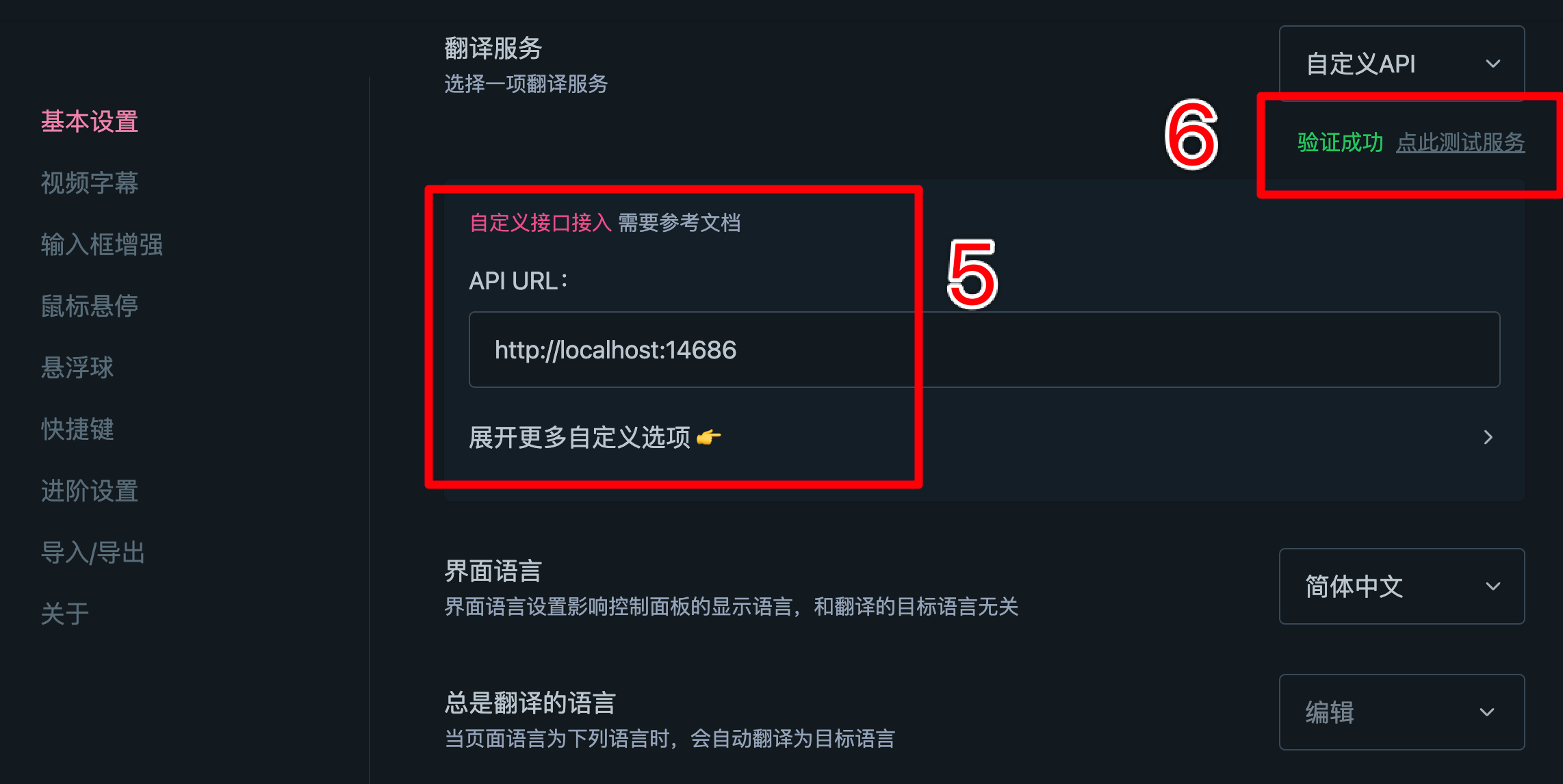
之后,选择“基本设置”,选择自定义接口(⑤),测试一下是否能正常调用(⑥)。
其他可能有用的信息
有关模型选择的问题。我本地测试了 Qwen 1.5 7B、14B、70B 几种模型,尽管感觉上 70B Q3 的翻译质量好得多,但在 M3 芯片上生成速度太慢,每秒只能输出 17 tokens 约 8 个中文字。
换 13B 速度够用,但是非常容易出现停止词问题。最后日常翻译我还是选择 7B,速度飞快,还不发热。就是同样的提示词,7B 的返回要加不少戏。成文之际又换回了 13B。
说到提示词。如果你用的不是 Qwen 而是 LLama2 或者不是从高质量中文语料中训练来的模型,那对应的提示词肯定要换。可以参考:Polyglot superpowers。
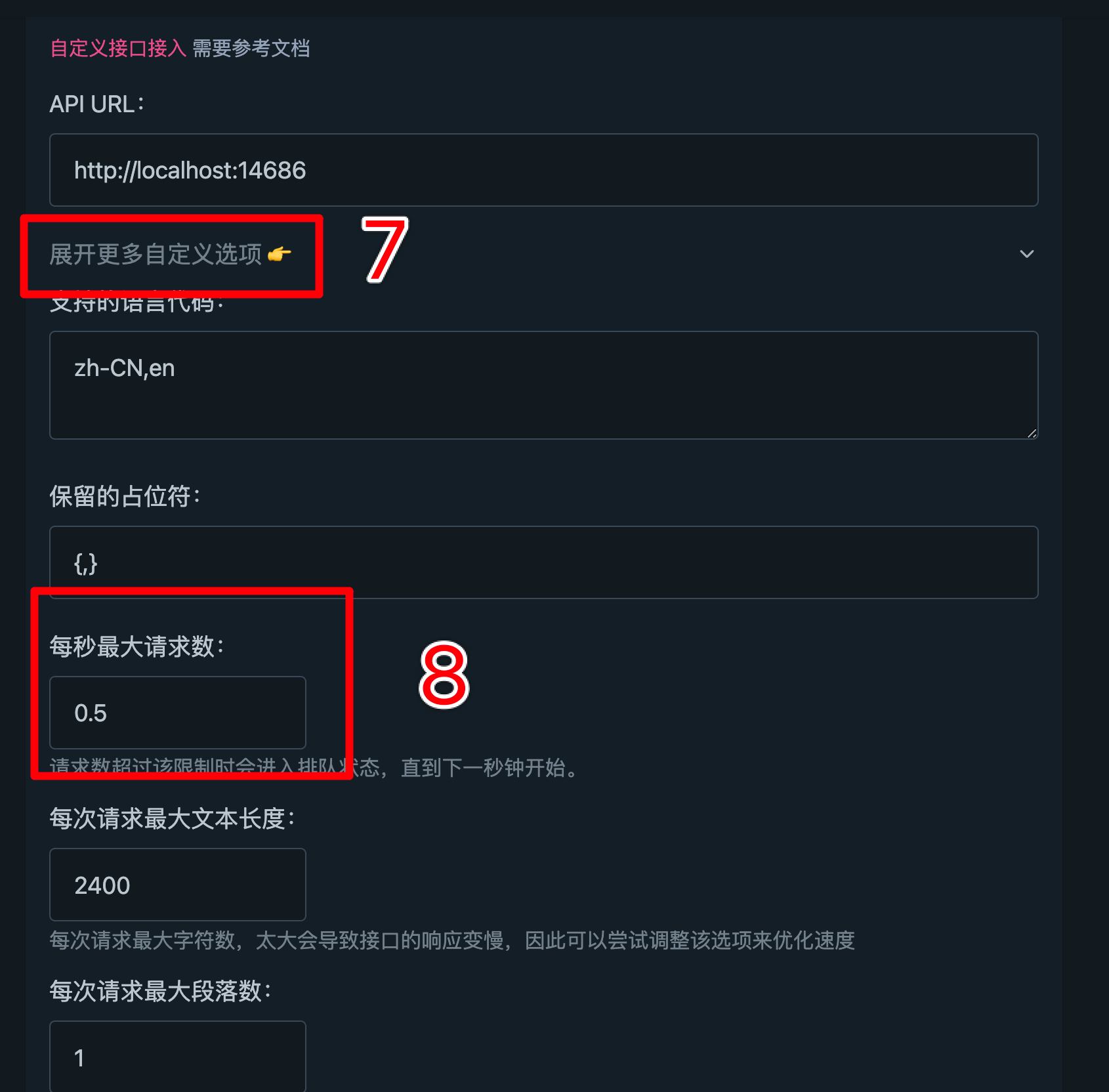
有关请求速度的设置。由于沉浸式翻译本身自带请求结果缓存,所以无需担心同一个页面的翻译或是重复句子的翻译会多次调用。但本地模型毕竟比不上第三方 API 的速度,如果不想写更多代码(如在本地服务器转发时做更复杂的并发控制),
可以单纯地在自定义选项中(⑦)降低沉浸式翻译的每秒请求次数(⑧)。见下图,我的设置是每两秒请求一次(即翻译一个句子)。沉浸式翻译能自动断句,所以不用担心单个句子太长。成文之际已经把断句关掉了,主观而言,
关断句后翻译速度和准确率要更好。
整个链路可替代的选项。本文使用的工具是 LMStudio 本地部署、Qwen1.5、LMStudio Server、NodeJS Proxy、沉浸式翻译插件。在 BiliBili 评论区也见过其他方案,比如有用 Ollama 部署的, 用 mT5 的模型翻译的,用全局翻译插件 Bob 替代沉浸式翻译的。总得来说没有见过满分的技术栈。可玩性还很高,如果有时间投入的话。
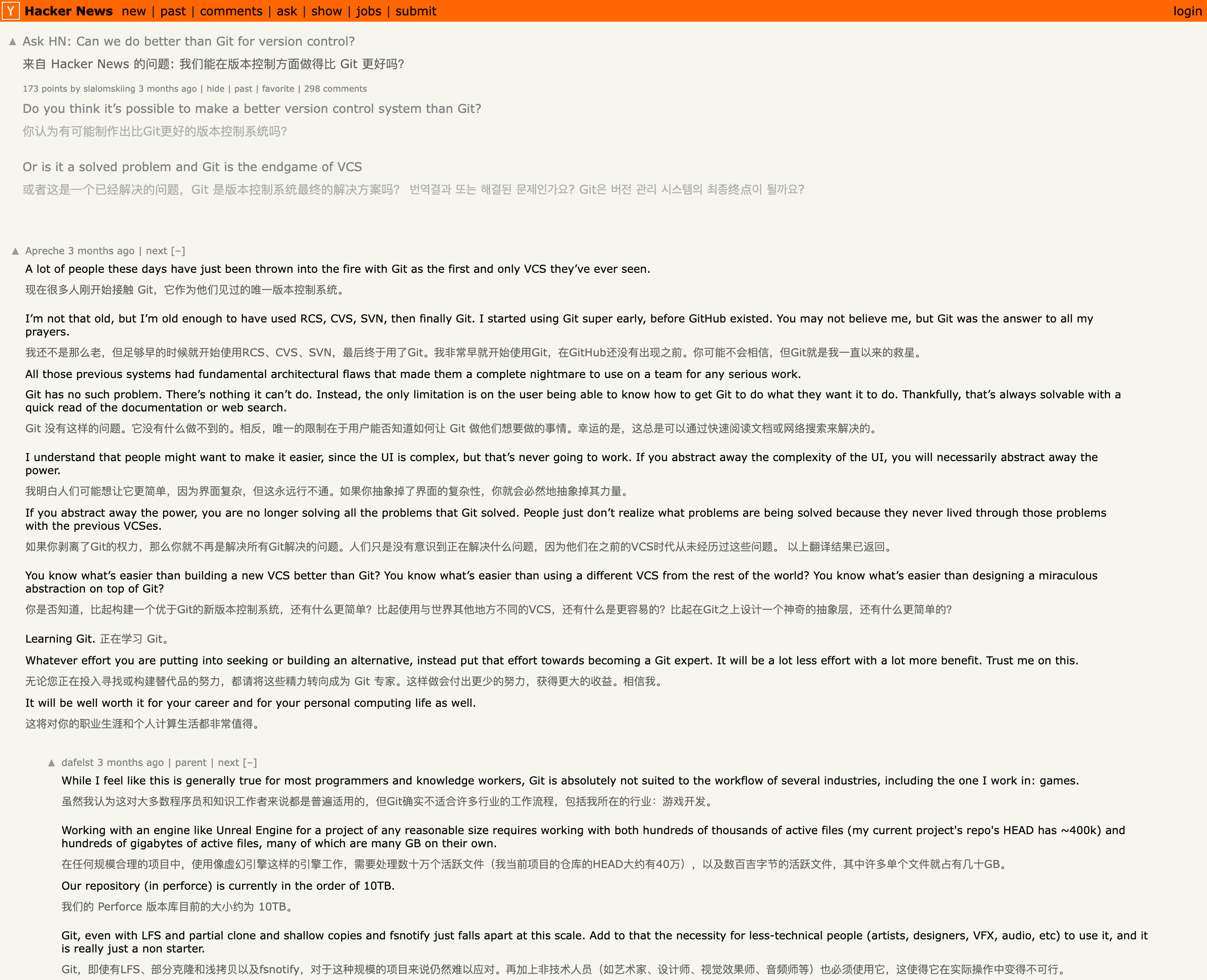
最后展示一下翻译效果,分别是 Qwen 1.5 7B q5、14B q6 和 70B q3 的翻译效果。使用的是同一个网页:Can we do better than Git for version control?

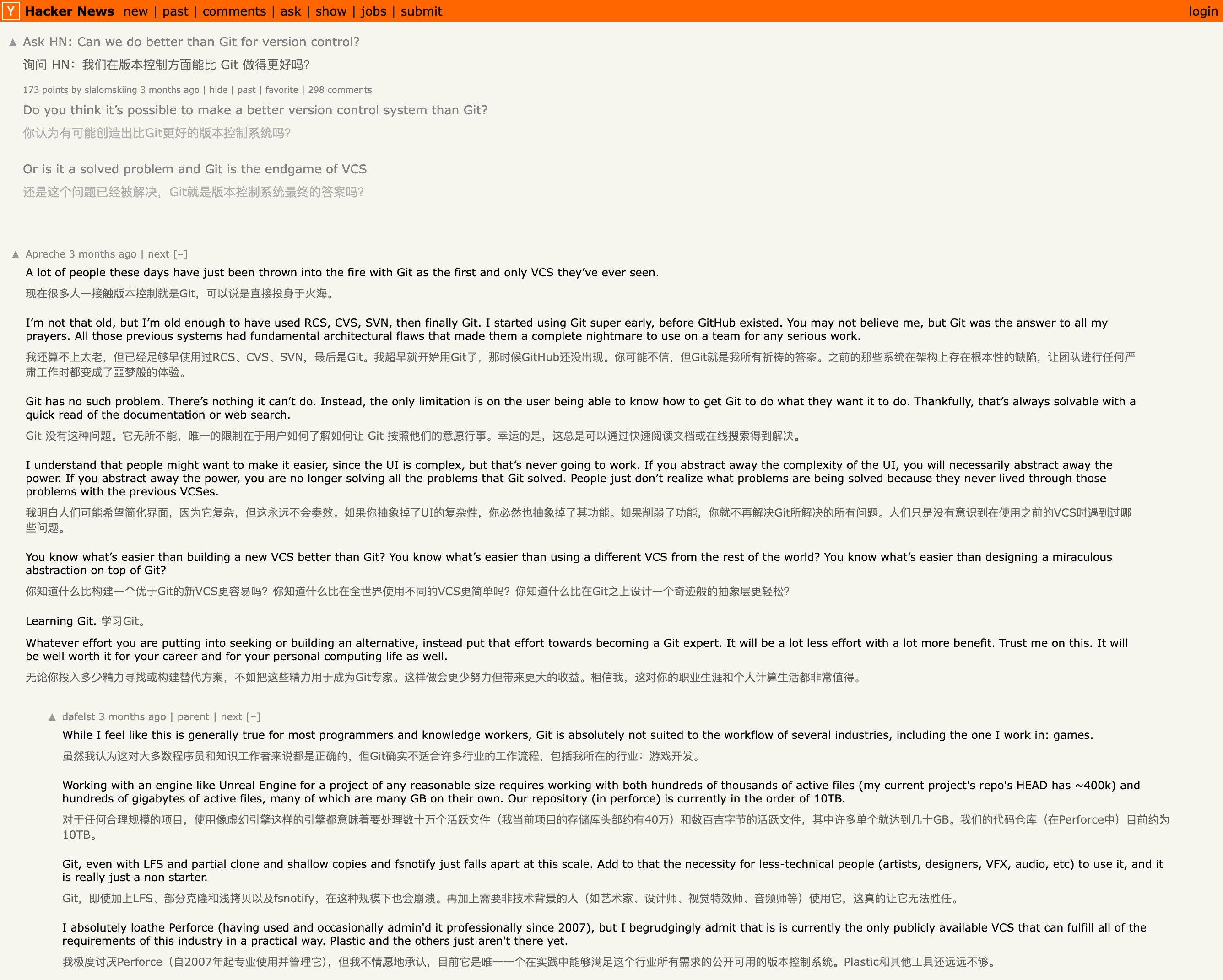
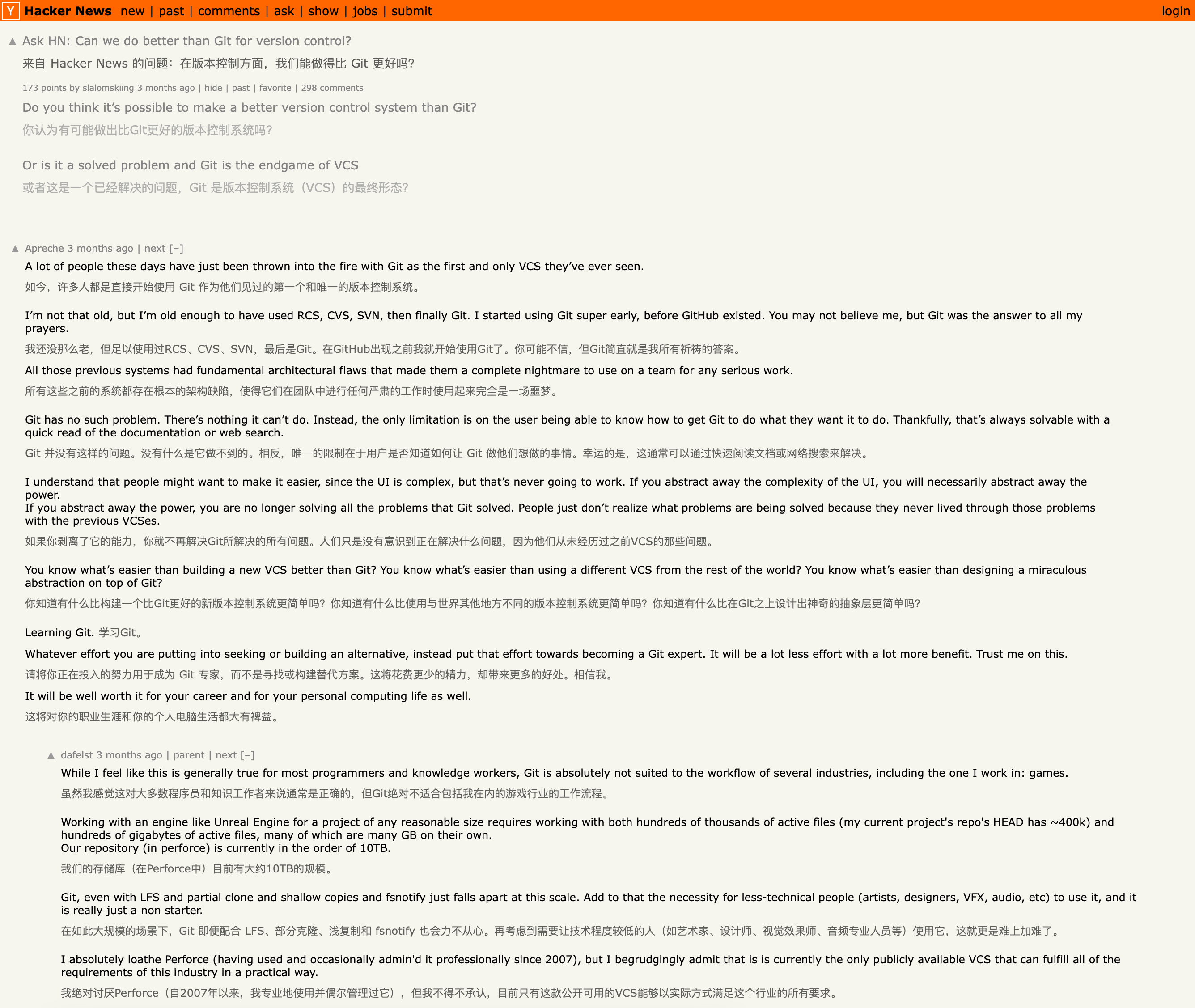
我在 BiliBili 看到别人说 Q4 程度量化对精度的影响较小,但如果小于 Q4,精度会下降很多。不过从对照组来看,14B q6 的翻译质量确实完胜 14B q2。