Ⓜ️ Mini CSS Parser
前言
Vue 源码中包含 HTML Parser,随着大家在框架方向的深入学习(卷),不免要开始接触一些编译解析相关的东西。社区很多看 Vue 源码时总结的 HTML Parser 的文章,但是很少有介绍 CSS Parser 的文章。 今天借着在开发时碰到的一个问题,给大家简单介绍一下 CSS Parser 的基本流程。
我的项目使用 micro-app 框架作为微前端框架。使用 micro-app 时,由于开启了样式隔离功能,子应用加载的 CSS 会被解析器解析,在选择器前增加一个子应用属性选择器前缀。代码示例见下。我碰到的问题是,如果 CSS 源码中带嵌套语法,那么解析就会失败。
/* css 源代码 */
.a {
z-index: 1;
.b {
z-index: 2;
}
}
/* 期待转化得到的代码 */
micro-app[name="test-app"] .a {
z-index: 1;
.b {
z-index: 2;
}
}
/* 实际得到的代码 */
micro-app[name="test-app"] .a {
z-index: 1;
.b {
z-index: 2;
} /* -> 到这里就停了 */
CSS 的组成部分
要理解 CSS 是怎么解析的,就要先清楚 CSS 是由哪几部分组成的。由我们平常见得最多的普通 CSS 代码开始说起,见下图,基本的 CSS 代码的组成部分包含规则集(rules)、选择器(selector)、选择器(declares)、 属性(property)、值(value)这五个部分。 规则是由属性和值组成的<abbr title="declaration"
声明、声明与括号形成的声明块再加上选择器组成, 而一条或多条规则组合成了规则集1。
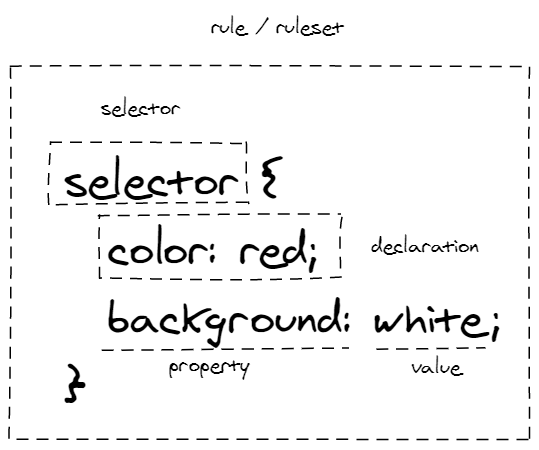
图中没有包含 at-rule 的部分,哦,还少了注释部分~ 由于注释是 CSS 中语法最简单的部分,我们从解析注释开始代码部分的解读吧。
流程速览
解析注释
可能许多人不了解 CSS 的注释风格,这里先说明一下,原生 CSS 仅支持斜杠星号风格注释,不支持双斜杠注释,所以解析器并未处理双斜杠的情况。
解析注释的函数是一个 while 循环,从代码开头开始匹配,每次循环解析一条注释,直到代码开头没有注释为止。
class CSSParser {
private matchComments() {
while (this.matchComment());
}
private matchComment() {
// 快速跳过非注释部分代码
if (this.cssText.charAt(0) !== "/" || this.cssText.charAt(1) !== "*") {
return false;
}
// ...
return true;
}
}
在选择解析注释内容的方法上,micro-app 没有使用正则,而是用了下标递增的办法。暂不清楚原因,感兴趣的小伙伴可以试试几种相关办法的性能对比。
let i = 2;
while (
this.cssText.charAt(i) !== "" &&
(this.cssText.charAt(i) !== "*" || this.cssText.charAt(i + 1) !== "/")
) {
++i;
}
i += 2;
let commentText = this.cssText.slice(2, i - 2);
/* ... */
this.cssText = this.cssText.slice(i);
注释的正文结果保存在了变量 commentText 中,这样可以判断 commentText 的内容来实现通过注释禁用某个选择器、禁用某行的样式隔离之类的功能。比如想让 .test2 选择器不被 scoped 规则覆盖,
我们可以在业务代码中这样写。
/*! scopecss-disable-next-line */
.test2 {
background: url(/test.png);
}
输入输出
“解析注释”中“解析”实际指对输入的 CSS 源文件待处理部分以及处理好的输出部分做出改变。这里引申出解析器里两个关键状态,cssText 和 result,分别代表待解析的内容和最终输出结果。
cssText 随着循环应当逐渐减小直到为空,此时代表解析完成。result 能被内部方法 recordResult 改变,比如如果要把注释的正文内容记录到输出结果,可以这样使用:
this.recordResult(`/*${commentText}*/`);
// 相当于:this.result += `/*${commentText}*/`
解析规则集
规则集的解析是整个解析的核心过程。原理与解析注释类似,也是一个 while 循环。每一轮循环都会尝试匹配一条规则,并且将多余的注释和空白字符匹配出来。
private matchRules (): void {
this.matchLeadingSpaces()
this.matchComments()
while (
this.cssText.length &&
this.cssText.charAt(0) !== '}' &&
(this.matchAtRule() || this.matchStyleRule())
) {
this.matchComments()
this.matchLeadingSpaces()
}
}
匹配注释我们知道它是使用了下标递增 + Slice 的方法,匹配空白这里则是用的一个非常简单的正则。见下 matchLeadingSpaces 函数。
private matchLeadingSpaces (): void {
this.commonMatch(/^\s*/, false)
}
可以想象,commonMatch 应当会对状态 cssText 和 result 做一些操作。实际上,commonMatch 两个参数分别是用于匹配 cssText 的正则,及跳过标记。如果在待匹配内容中匹配到了字符串,
便把匹配的内容从中移除;跳过标记则意味着当确认跳过时,匹配的内容将不会被记录到输出结果中。以上面的 matchLeadingSpaces 函数举例,如果在待匹配内容中匹配到空白字符,那么会将其丢弃不做处理。
commonMatch 可谓是解析器匹配逻辑的核心,只要理解了它,那么我们回到上面提到的样式规则匹配 matchStyleRule,会发现其过程非常简单。简单来说只有三步,匹配选择器、记录解析后的选择器、解析(并记录)声明。
结束条件只有成功解析以及选择器解析报错或声明解析报错。
private matchStyleRule (): boolean | void {
const selectors = this.formatSelector(true)
this.scopecssDisableNextLine = false
if (!selectors) return parseError('selector missing', this.linkPath)
this.recordResult(selectors)
this.matchComments()
this.styleDeclarations()
this.matchLeadingSpaces()
return true
}
首先是匹配选择器的部分。以 .a,.b{color:red} 为例,首先匹配出{字符前的部分即.a,.b作为选择器的正文,然后使用,分割选择器,并给选择器加上 prefix,
最终返回micro-app[name="subapp"] .a, micro-app[name="subapp"] .b。刚才提到可以在业务代码中使用注释给特定选择器禁用 prefix 前缀,相关的代码的实现也在这个函数中。
const selectors = this.formatSelector()
private formatSelector (skip: boolean): false | string {
// 匹配选择器正文
const m = this.commonMatch(/^[^{]+/, skip)
return m[0].replace(/(^|,[\n\s]*)([^,]+)/g, (_, separator, selector) => {
// 如果检测到选择器被禁用则跳过添加前缀步骤
if (...) {
const prefix = this.prefix // micro-app[name="subapp"]
selector = prefix + ' ' + selector
}
return separator + selector
})
}
匹配完选择器后,声明便是剩下的包含在左右花括号的内容。匹配过程是一个递归,以遇到}作为结束条件。如果遇到斜杠/,则尝试停止声明匹配并开始注释匹配。总之,}之前的内容都作为当前选择器的声明,添加到cssText中。micro-app 框架会对 CSS 资源中的 URL 补全为主应用的完整路径这个功能也是在这个函数中实现,有兴趣的话可以查看其完整代码。
private matchAllDeclarations (): void {
let cssValue = (this.commonMatch(/^[^}/])*/, true) as RegExpExecArray)[0]
this.recordResult(cssValue)
// 递归退出条件
if (!this.cssText) return
if (this.cssText.charAt(0) === '}') return
// extract comments in declarations
if (this.cssText.charAt(0) === '/' && this.cssText.charAt(1) === '*') {
this.matchComments()
} else {
// 如果不是注释则忽略中断,继续匹配声明
this.commonMatch(/\/+/)
}
return this.matchAllDeclarations()
}
解析at-rule
流程中最繁琐的部分,是匹配 @media、@import、@charset 等 at-rules。
每一种规则的语法都不同,要怎么处理才合适呢?
这里,micro-app 把 at-rule 分为了三组:
- 类似
@charset "utf-8";为一组,包括@import、@charset、@namespace等。 - 类似
@media (w < 100px) { .selector { xxx: xxx } }为一组,包括@supports、@font-face、@document等。 - 类似
@font-face { unicode-range: 'xxx' }为一组,包括@font-face、@page、@key-frames等。
第一组,@charset 所在的第一组规则的规则正文内容从 @ 开始到 ; 结束,比如 @charset "utf-8"; 就是一条完整的声明;
第二组,@media () {} 的花括号部分可能包含选择器,所以其正文内容需要重新进入 matchRules 匹配选择器以及声明。
第三组,@font-face {} 的花括号部分仅包含声明,不包含选择器,所以只需要进入 matchAllDeclarations 匹配声明即可。
解决问题
回到文章开头的问题,如果要给这个 CSS Parser 增加原生的嵌套功能,见下代码,可以仅用十行简单实现。
+ private matchAllDeclarations (nesting = 0): void {
let cssValue = (this.commonMatch(/^[^}/])*/, true) as RegExpExecArray)[0]
this.recordResult(cssValue)
// 递归退出条件
if (!this.cssText) return
- if (this.cssText.charAt(0) === '}') return
+ if (this.cssText.charAt(0) === '}') {
+ if (!nesting) return
+ this.commonMatch(/}+\s*/)
+ return this.matchAllDeclarations(nesting - 1)
+ }
// extract comments in declarations
if (this.cssText.charAt(0) === '/' && this.cssText.charAt(1) === '*') {
this.matchComments()
} else {
// 如果不是注释则忽略中断,继续匹配声明
this.commonMatch(/\/+/)
}
+ if (this.cssText.charAt(0) === '{') {
+ this.commonMatch(/{+\s*/)
+ nesting++
+ }
- return this.matchAllDeclarations()
+ return this.matchAllDeclarations(nesting)
}
最终 CSS Nesting 解析成功。
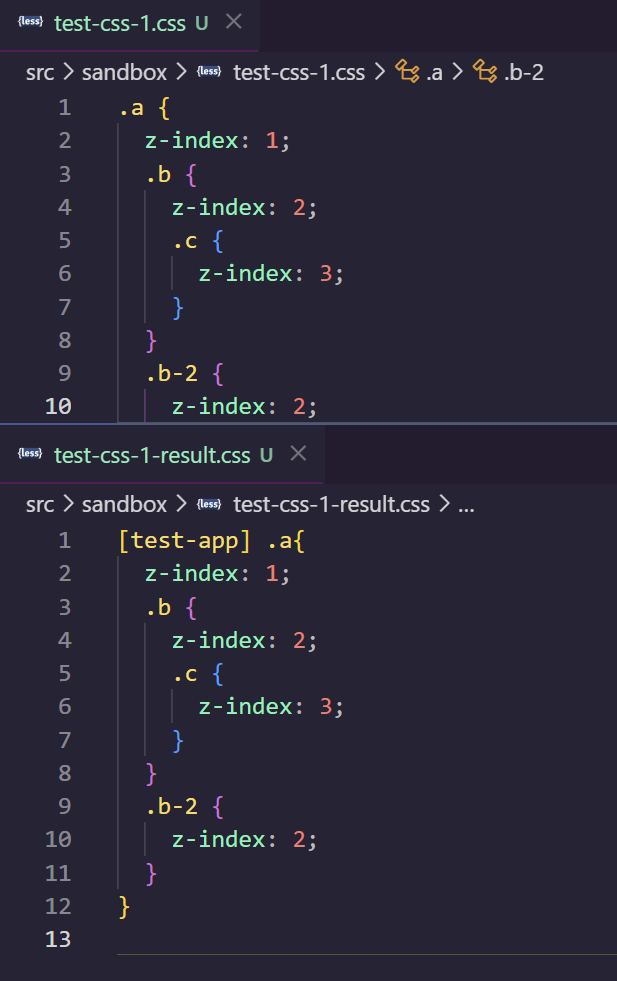
结语
整个 CSS Parser 的代码简单,功能强悍,耐人寻味。不过有许多边界条件没有处理好,尤其是引入了使用注释禁用样式隔离功能后,匹配注释变得更复杂且易错了。
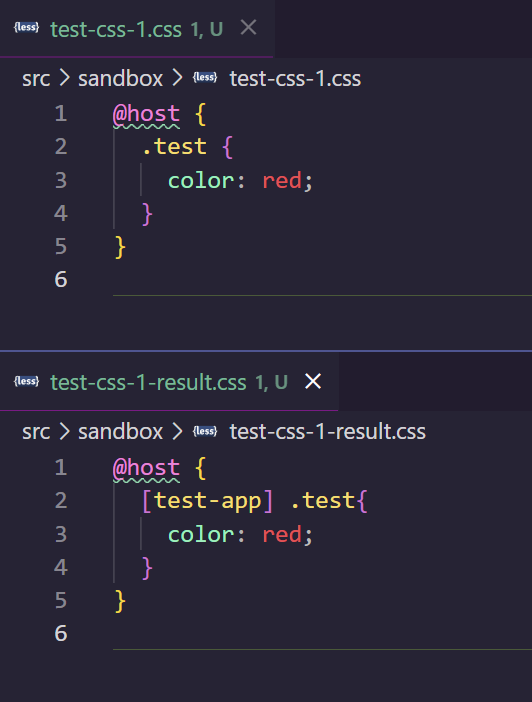
- 注释不能和选择器等混用(以下 result 文件代表解析结果)。
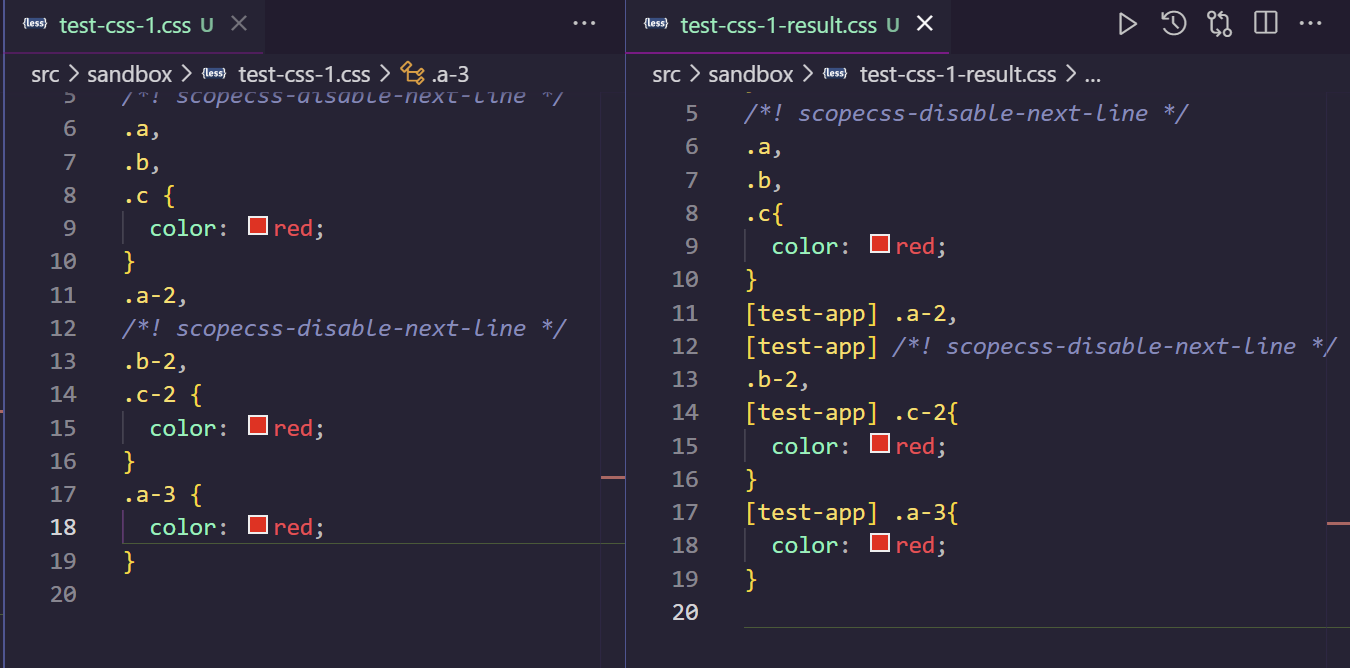
- CSS 字符串值可能意外启用编译器的特殊功能。
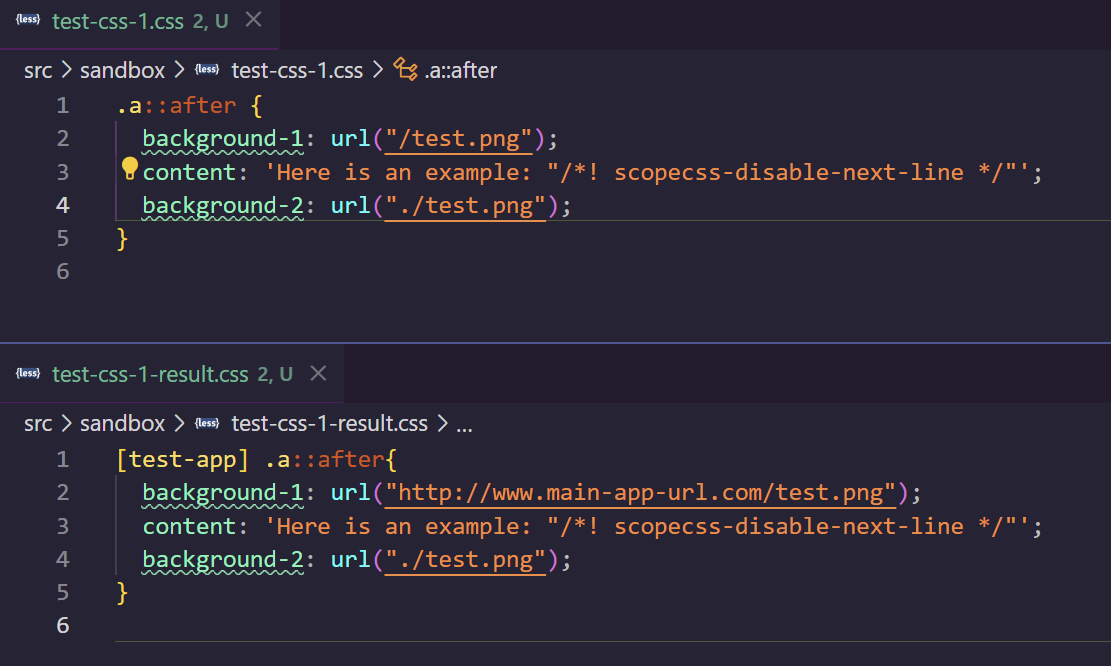
- 错误的
@host规则匹配。猜测是想匹配:host但是手滑写成了@host。
private hostRule =
this.createMatcherForRuleWithChildRule(
/^@host\s*/,
'@host'
)
在实际项目中,考虑到性能和可维护性的平衡,为了使代码不变得过于复杂,没有必要去完善“边界功能”。运行时的解析应当尽量简单且运行快速,并保持一定的容错:不规范的 CSS 代码在浏览器中本身就能运行,再者,解析器是一个容易带来代码性能和体积瓶颈的地方,要不然 VueJS 也不会分全局构建和运行时两个版本的编译产物。
鉴于 CSS 在部分语法上的灵活性,如果从降低维护难度的角度考虑优化这个 CSS Parser,可能从以下方向:
- 在规则匹配部分使用黑名单机制而不是白名单匹配。就
at-rule等灵活语法而言,如果浏览器支持新的@xxx语法,黑名单机制编写的代码不需要对@xxx做额外处理;而白名单机制需要手动处理。 - 在复杂的解析器部分使用外部依赖,如使用类似
lightingcss-wasm等方案。
关于样式隔离,作者两年前专门写了文章介绍,不过时效性稍有不足,没有涉及解析器的具体流程,写得更多是解析器在整个微前端框架中的作用,也可作为补充阅读。
最后,微前端框架中的 CSS 的有很多中实施办法,采用一些办法可以抛弃运行时解析。em... 也许以后有机会聊一聊(咕一咕)。
增订 | 2024 年 1 月 28 日
相关实现和测试用例见这个 Issue
Footnotes
- 比较完整的 CSS 语法参见:https://developer.mozilla.org/zh-CN/docs/Web/CSS/Syntax ↩