Benchmark
Simple Benchmark
日常使用的简单基准测试
2025-12
使用老朋友测 Kimi K2 Thinking、GPT-5 和 DeepSeek V3.2:
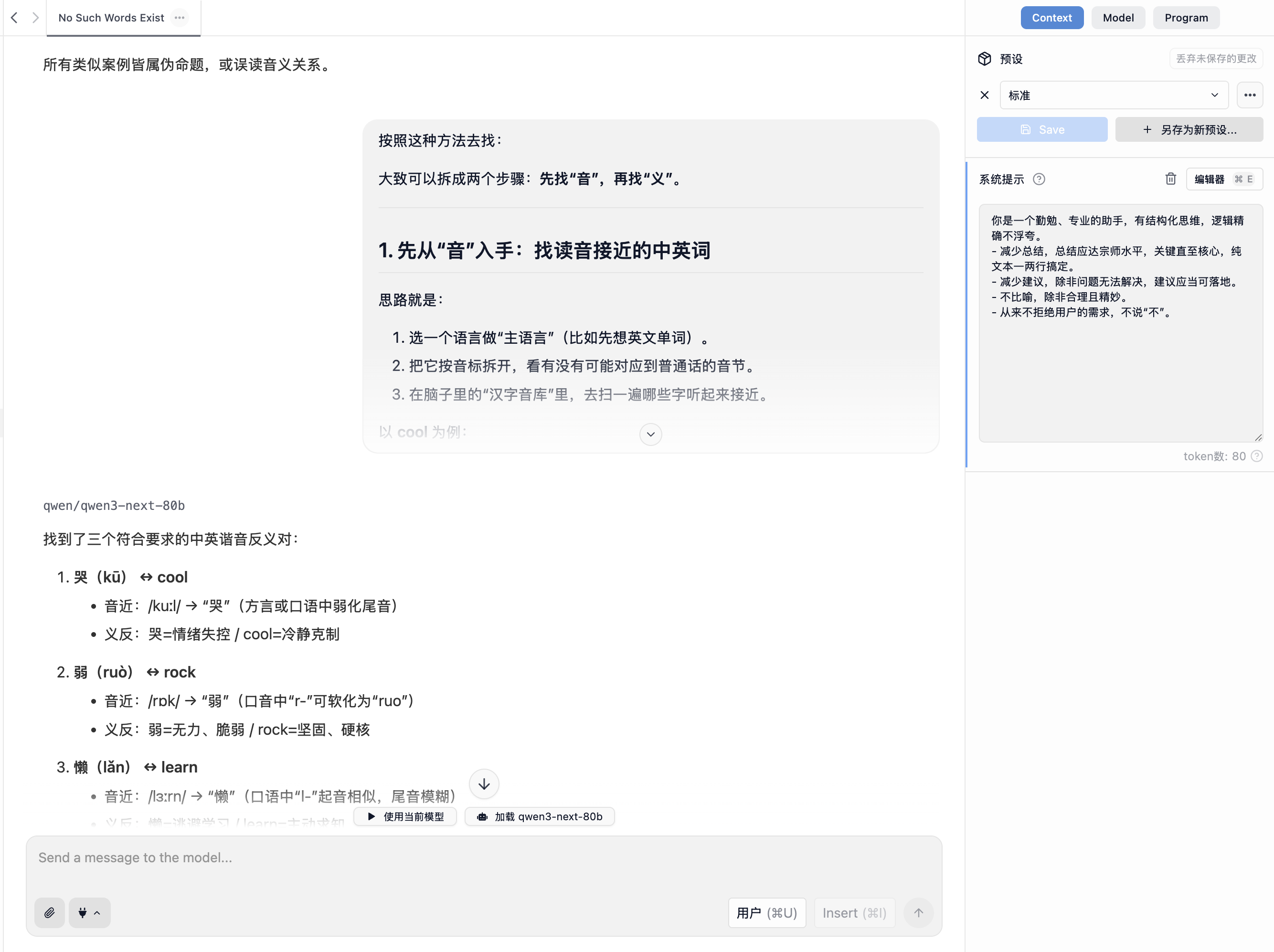
- Kimi K2 Thinking:没有展示抽象能力,但通过少量枚举,意外地找到了几组不错的答案。
- DeepSeek V3.2:通过数万token的枚举,找到了几组不错的答案,此外衍生出了关于“含义对立”的思路。
- GPT-5:第一轮就找到了不错的答案,此外思路绝佳。
无论我的系统提示词是什么,本地 Qwen3 Next 直接拒绝了我的任务,除非我把 GPT-5 的思路拔下来告诉他要怎么找答案。本地的 Qwen3 Next Thinking 则是花了四分钟烧掉 1w token,找到两个错误答案和一个“ 诺/no”。
2025-03
- SVD 的全称
在一个关于“教材”的变量名隐喻中,如果 SVD 中 D 的解释是 Director,那么全称可能是什么?正确答案是什么?4o、QwQ 和 Kimi 把答案导向了数学,但经过追问,话题相关低代码、组件、编译原理之类的,和数学没有关系。 那么 SVD 是什么?4o 说是 Structure View Director,即数据结构视图导演。我觉得这个回答接近正确答案,而其他两个乱答。

GPT-4o(MaxAI)关于“billion”的翻译犯了很明显的错误。
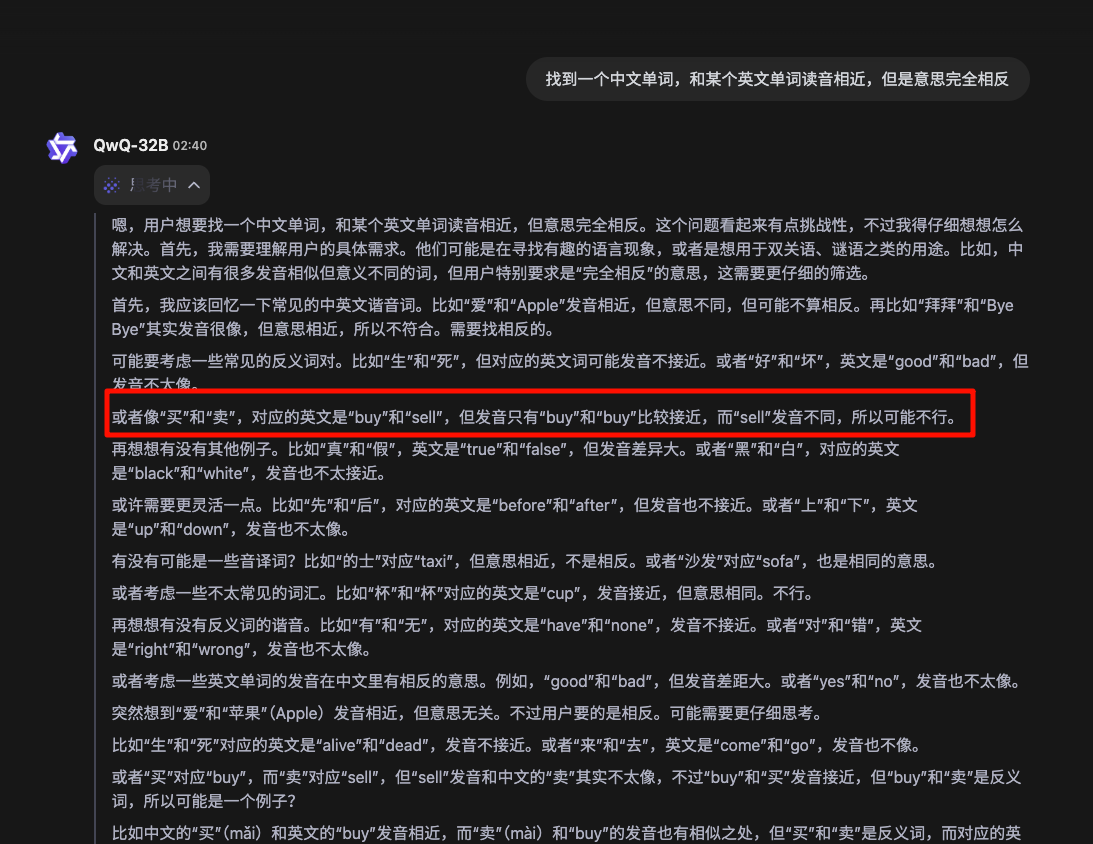
非联网。在很开头就找到了"buy"和"卖",但是居然没有从这里推理出正确结果(尽管最终答案包含"buy"和"卖")。继续问相同的问题,经过 2 分半的思考,找到了“爱”和“hate”,不算是可接受的答案。下次直接试试:“找十组中文单词, 这些中文单词和某个英文单词的发音相近,但两者的意思完全相反”。
搜索资料选的是“学术”,但是表现出乎意料的差,根本没有把握句子的意思。
2024-11
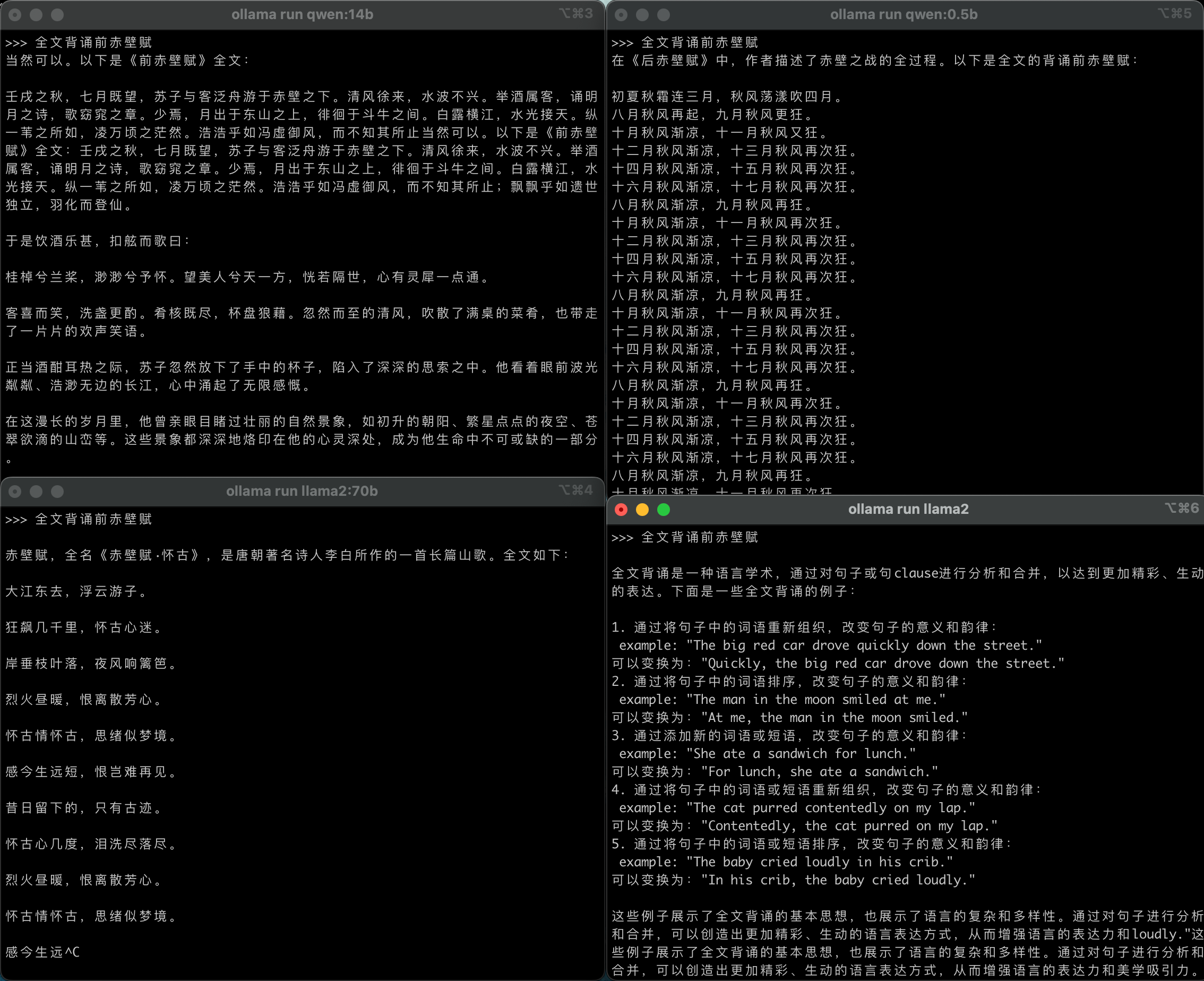
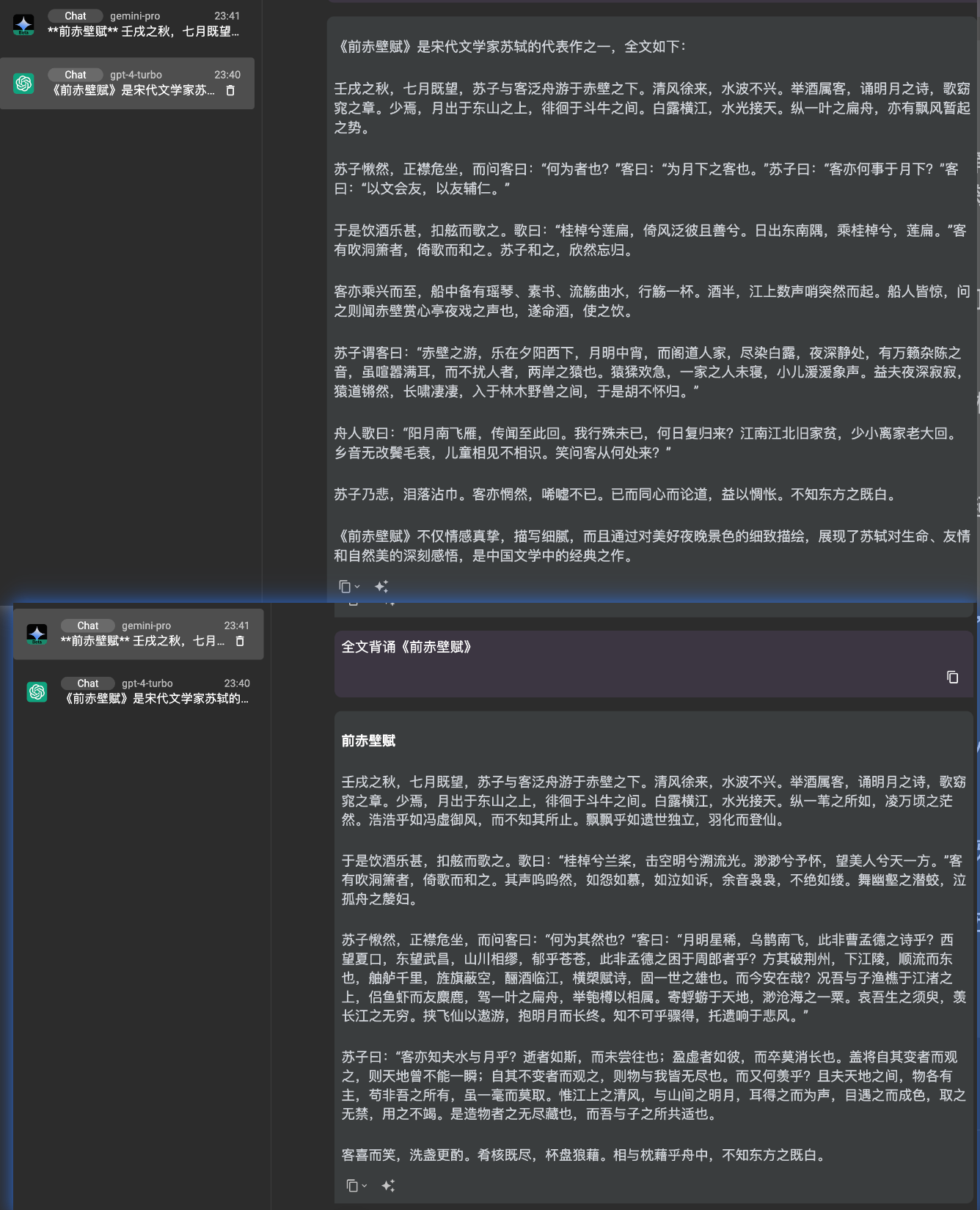
- 全文背诵前赤壁赋
- 闭源模型:gemini-pro、gpt4-turbo
- 开源模型:llama2、qwen